
Published on: 2025-08-11

This guide demonstrates how to integrate Ollama with FastAPI and a self-hosted n8n workflow, enabling AI-powered question answering based on data scraped from Shopify documentation.
📌 Overview
The workflow leverages n8n for orchestrating tasks, FastAPI for processing requests, and Ollama for local AI model inference.
In this setup, FastAPI handles a single request that performs both embedding generation and chat-based answering, using search results gathered via the Serper API.
⚙️ Workflow Steps
1 Trigger via Webhook
A webhook initiates the process. On this workflow example:
http://localhost:5678/webhook-test/shopify-dev-scrape?question=implement+hydrogen+and+oxygen+for+theme
2 Format Search Query
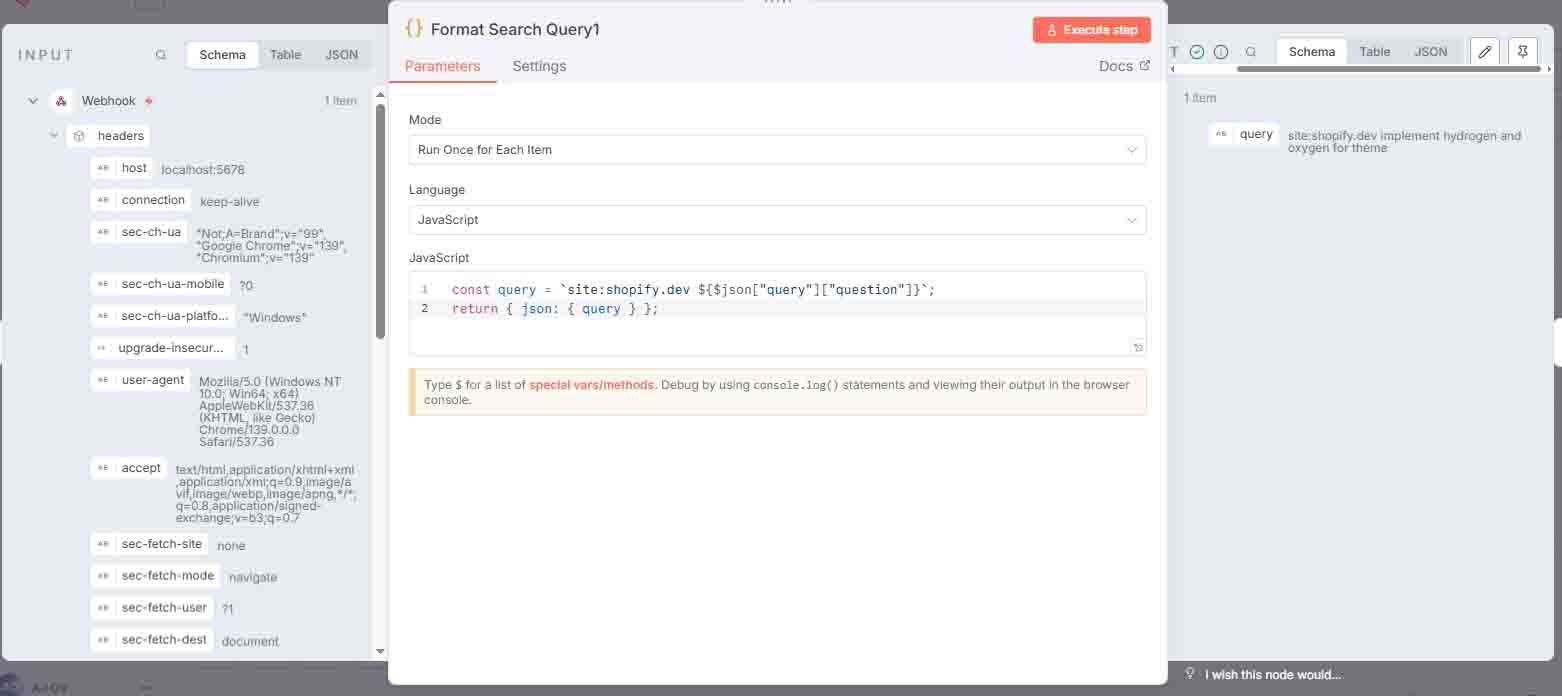
JavaScript code formats the query to target searches exclusively on the shopify.dev website.
3 Search Shopify.dev
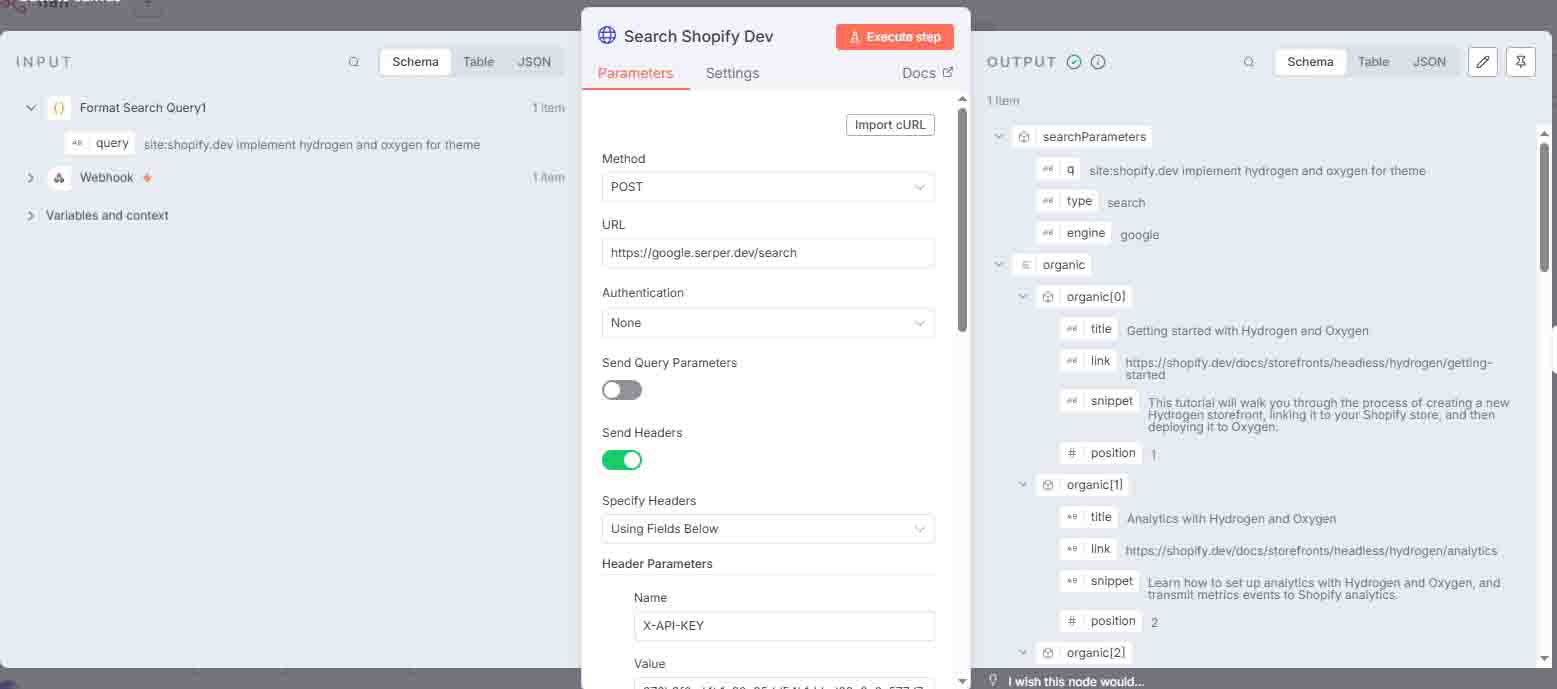
Executes a search query using Serper API (requires a free API key from serper.dev).
4 Get Top Result
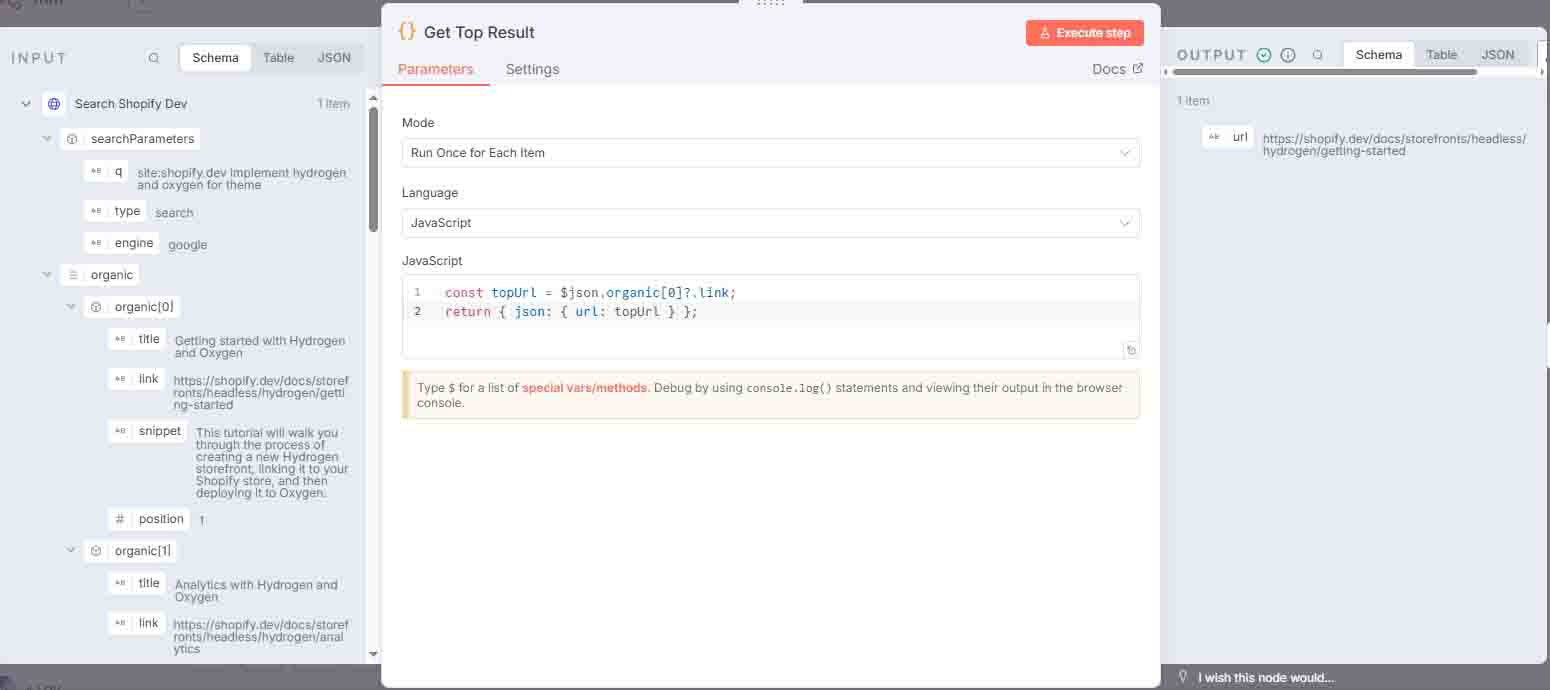
Selects only the top search result and returns it as json.url.
5 Fetch Shopify Page
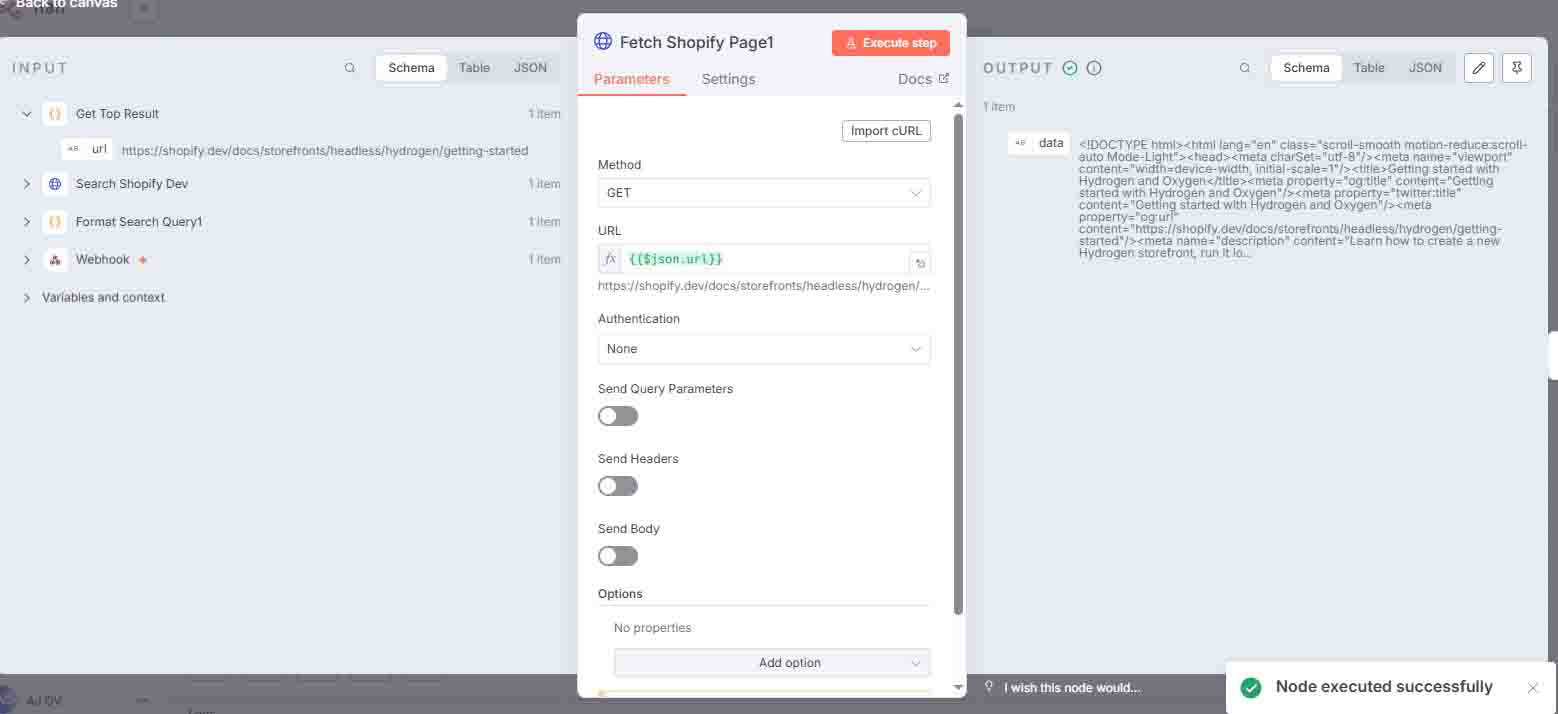
Retrieves the HTML content from the top search result.
6 HTML Extraction

Extracts specific content from the HTML body, saving it as datahtml.
7 HTML File Conversion

Converts datahtml into a file, which will be attached as a document for the “Ask Ollama” workflow.
8 Ask Ollama
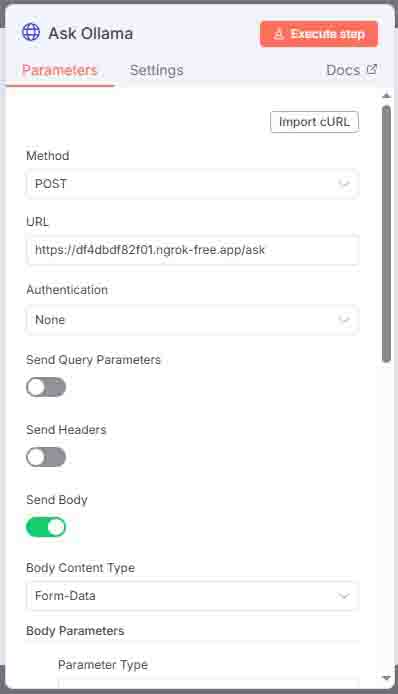
Sends the processed HTML document to the FastAPI endpoint for answering.
Requires both FastAPI and Ollama to be running via ngrok, with updated forwarding URLs.
🔹 FastAPI Setup
Python Environment Setup (Using uv):
uv venv
.venv\Scripts\activate
uv pip install -r requirements.txtrequirements.txt
fastapi
uvicorn
torch
openai
ollama
lxml
python-multipart
numpy
aiollama.py
#aiollama.py
import torch
import ollama
import re
from fastapi import FastAPI, UploadFile, File, Form
from fastapi.responses import JSONResponse
from openai import OpenAI, OpenAIError
app = FastAPI()
client = OpenAI(
base_url='https://YOUR_FREE_PUBLIC_URL.ngrok-free.app/v1',
api_key='dolphin-llama3'
)
# 🔹 Get relevant context
def get_relevant_context(query, vault_embeddings, vault_content, top_k=3):
print("→ Generating embedding for query....")
input_embedding = ollama.embeddings(model='mxbai-embed-large', prompt=query)["embedding"]
print("✓ Query embedding done.")
input_tensor = torch.tensor(input_embedding).unsqueeze(0)
cos_scores = torch.cosine_similarity(input_tensor, vault_embeddings)
top_k = min(top_k, len(cos_scores))
top_indices = torch.topk(cos_scores, k=top_k)[1].tolist()
return [vault_content[i].strip() for i in top_indices]
# 🔹 Main chat wrapper
def ollama_chat(
question,
system_message,
vault_embeddings_tensor,
vault_chunks,
conversation_history,
model_name="dolphin-llama3"
):
print("→ Getting relevant context...")
relevant_context = get_relevant_context(question, vault_embeddings_tensor, vault_chunks)
print(f"✓ Got {len(relevant_context)} relevant chunks.")
context_str = "\n".join(relevant_context)
user_input_with_context = context_str + "\n\n" + question if relevant_context else question
conversation_history.append({
"role": "user",
"content": user_input_with_context
})
messages = [{"role": "system", "content": system_message}] + conversation_history
print("→ Sending request to Ollama model...")
try:
response = client.chat.completions.create(
model=model_name,
messages=messages
)
except OpenAIError as e:
print("❌ OpenAIError:", e)
raise
except Exception as e:
print("❌ Unexpected Error:", e)
raise
print("✓ Received response from Ollama.")
# ✅ Append assistant's response to history
assistant_reply = response.choices[0].message.content
conversation_history.append({
"role": "assistant",
"content": assistant_reply
})
return {
"relevant_context": relevant_context,
"response": assistant_reply
}
# 🔹 FastAPI Endpoint
@app.post("/ask")
async def ask_from_uploaded_html(file: UploadFile = File(...), question: str = Form(...)):
print("→ Reading uploaded file...")
contents = await file.read()
print("✓ File read.")
text = re.sub(r'\s+', ' ', contents.decode("utf-8")).strip()
print("→ Splitting into chunks...")
sentences = re.split(r'(?<=[.!?]) +', text)
chunks = []
current_chunk = ""
for sentence in sentences:
if len(current_chunk) + len(sentence) + 1 < 1000:
current_chunk += sentence + " "
else:
chunks.append(current_chunk.strip())
current_chunk = sentence + " "
if current_chunk:
chunks.append(current_chunk.strip())
print(f"✓ Created {len(chunks)} chunks.")
print("→ Generating embeddings for chunks...")
vault_embeddings = []
for i, chunk in enumerate(chunks):
print(f" ↪ Embedding chunk {i+1}/{len(chunks)}")
response = ollama.embeddings(model='mxbai-embed-large', prompt=chunk)
print(f" • Vector: {response['embedding'][:10]}...") # print first 5 numbers only
vault_embeddings.append(response["embedding"])
vault_embeddings_tensor = torch.tensor(vault_embeddings)
print("✓ All embeddings generated.")
print("→ Calling ollama_chat()...")
conversation_history = []
result = ollama_chat(
question=question,
system_message="You are a helpful assistant that extracts the most useful info from uploaded documents.",
vault_embeddings_tensor=vault_embeddings_tensor,
vault_chunks=chunks,
conversation_history=conversation_history,
model_name="dolphin-llama3"
)
print("✓ ollama_chat() complete.")
print("Final Response:", result["response"])
return {
"question": question,
"relevant_context": result["relevant_context"],
"response": result["response"]
}
Run the API:
uvicorn aiollama:app --reload🔹 Ollama Setup
Pull required models:
ollama pull mxbai-embed-large
ollama pull dolphin-llama3🔹 NGROK Setup
Ollama requires traffic policy configuration to accept requests from the FastAPI server. ngrok is used to tunnel requests securely during development.
Configure ngrok traffic policy (docs):
on_http_request:
- actions:
- type: add-headers
config:
headers:
host: localhost
9 Respond to User
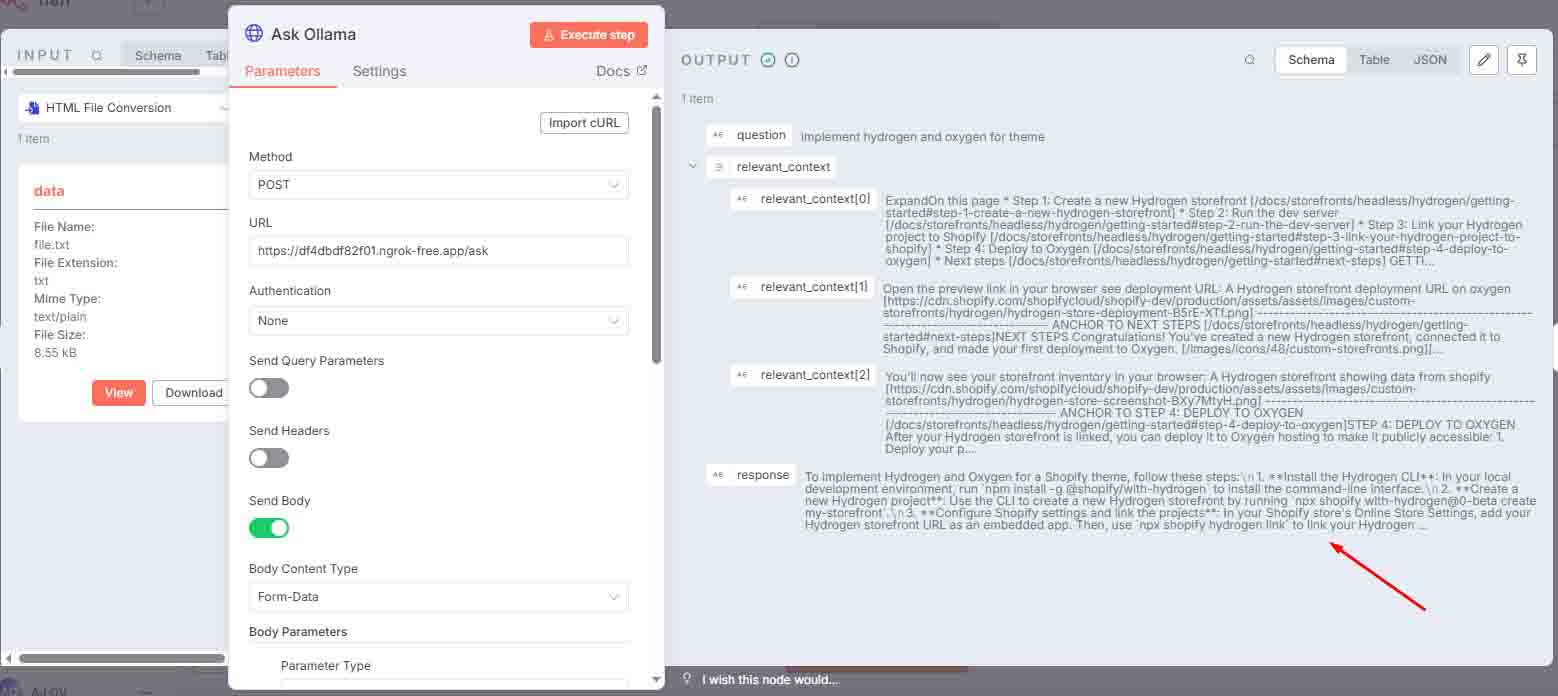
The webhook returns the AI-generated answer based on the question.
Behind the python running
Embedding:
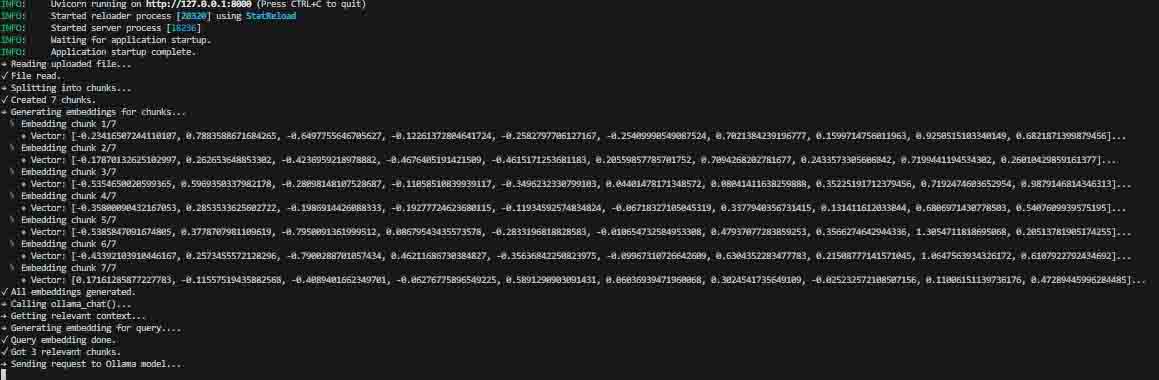
Chat API:
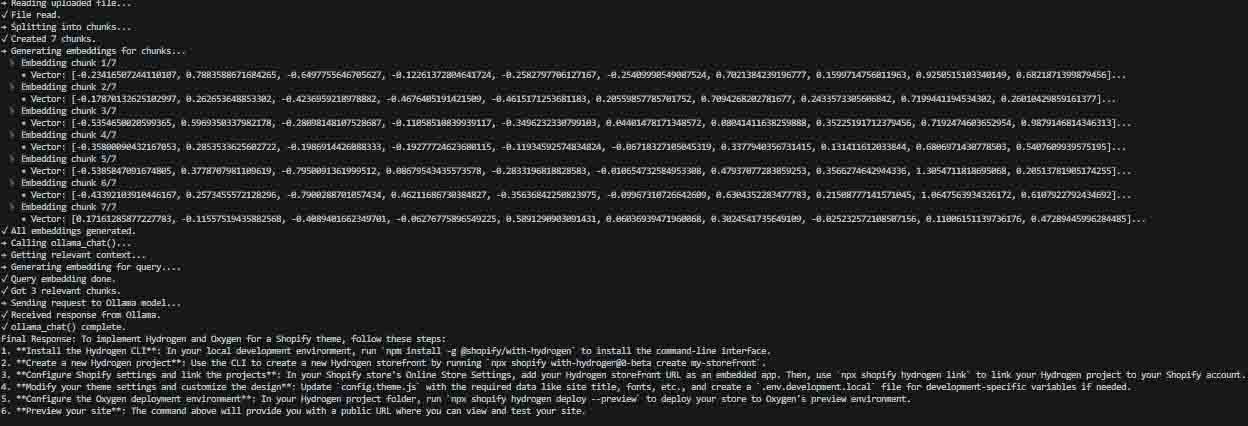
📄 Downloadable n8n Workflow
The n8n JSON file can be downloaded and customized. Update the configuration to match your environment. (N8N Config file)
📝 TL;DR
Integrating Ollama with FastAPI and n8n enables private, local AI workflows ideal for tasks like:
- Internal or confidential documentation search and Q&A
- Automating technical knowledge retrieval
- Building low-code AI integrations with n8n for domain-specific assistants
This approach combines local AI privacy, low-code orchestration, and flexible FastAPI endpoints for rapid AI-powered tool development.